Automating repetitive tasks with Azure Functions.
Since the announcement of Azure Functions at Build 2016, I’ve been looking for an excuse to use them and I finally found it. Whenever we release a new version of our software, the actual process for building and committing to source control is really simple and takes just a few minutes. Then I get to spend at least 30 minutes on our internal job management system telling it about the new release and deprecating the old one. I then copy and paste the message from the release commit, enter it in to said system, then reformat it a bit and send it out to various internal users as release notes.
It’s just wrong when doing admin after a release takes more time than the actual release, plus I hate doing boring repetitive takes that I know a computer could do for me.
Enter Azure Functions, below is a quick diagram of how I wanted everything to work.
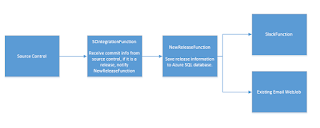
Source control calls a function when we commit. This function determines if it is a release by checking for a specific string in the message, it then puts a message on a queue to another function which will then enter the release details straight in to the database of our internal system (which we host in azure). This system doesn’t have an API so we’ll do it the old fashioned way with raw SQL.
If this is successful, it then puts messages on to 2 more queues, one is picked up by another function which posts the message in to Slack, the other goes off to a pre-existing web job which will email the release notes out.
Setup
I created a function app in the azure portal and hooked up a repository in my Bitbucket account to the function app.
I’m going to need to access a SQL database, so I put the connection string in my app settings same as for any other App Service app.
Let’s see what the code looks like.
This first function simply takes a small json payload over a http post, this structure of this is as below.
{
"Revision":"c1b49afddh7c",
"Author" : "Author Name",
"Created_At" : "2016-09-27T11:54:58+00:00",
"Log" : "Updated version to cpm 1.9.40
Added fluffy bunny controller",
"Branch" : "develop",
"Project":"cpm",
}#r "Newtonsoft.Json"
#r "Microsoft.WindowsAzure.Storage"
using System;
using System.Net;
using System.Threading.Tasks;
using Newtonsoft.Json;
using Microsoft.WindowsAzure.Storage.Table;
public static async Task<object> Run(HttpRequestMessage req, ICollector<CommitMessageTableEntity> commitLogTable, ICollector<<ommitMessage> releaseQueue, TraceWriter log)
{
string jsonContent = await req.Content.ReadAsStringAsync();
log.Info(jsonContent);
var data = JsonConvert.DeserializeObject<CommitMessage>(jsonContent);
log.Info(data.Log);
var te = new CommitMessageTableEntity();
te.Set(data);
try
{
commitLogTable.Add(te);
}
catch (System.Exception ex)
{
log.Info("An error occurred: " + ex.Message);
return req.CreateResponse(HttpStatusCode.OK, "An error occurred, see log for details.");
}
if(te.IsRelease) {
log.Info("This is a release, adding to queue so it gets added to Radius.");
releaseQueue.Add(data);
}
return req.CreateResponse(HttpStatusCode.OK, "Success");
}We log this to an Azure Storage table, I’ve no use for this currently but it costs practically nothing and is an easy way to check if the function was called if I have any problems in the future.
Then if the commit was a release commit, as defined by checking for the commit message to begin in a specific way, we put a message on a storage queue for the next function to be triggered. Note that I’m just adding to ICollector in both cases, the are no explicit references to Tables or Queues which is one of the things I really like about functions.
Here is the function.json, this defines all my inputs and outputs, note how the output queue name shows up as an Icollector
{
"bindings": [
{
"webHookType": "genericJson",
"type": "httpTrigger",
"direction": "in",
"name": "req"
},
{
"type": "http",
"direction": "out",
"name": "res"
},
{
"type": "table",
"name": "commitLogTable",
"tableName": "commitlog",
"connection": "SourceIntegrationSA",
"direction": "out"
},
{
"name": "releaseQueue",
"queueName": "releasequeue",
"connection": "SourceIntegrationSA",
"type": "queue",
"direction": "out"
}
],
"disabled": false
}The next function is the one that does all the work. There is a large amount of SQL in this function. The key for me was to get this up and running quickly and using SQL does that. Once it has proved it’s worth, I’ll tidy it up a bit with all the time it saves me!
I haven’t included the code here as it is very specific to me, all it does is use Dapper to insert a record for the new release and deprecate the previous one.
To import Dapper from Nuget, I added a project.json, see below.
{
"frameworks": {
"net46":{
"dependencies": {
"Dapper": "1.50.2"
}
}
}
}With this in place, whenever I redeploy my function, the Dapper Nuget will be downloaded for me to use.
Right at the end, once everything had been done, we pop a simple message on a queue to be picked up by another function that will send it to slack, and put the release notes from the commit message on another queue to be emailed out to internal staff members who will need to know.
The Slack function is really simple. It uses a Slack client class I found on the internet somewhere and just passes the message along.
About Alan Parr

I am a .Net developer based in the Midlands in the UK, working on Azure, .Net Framework, .Net Core, and just generally playing around with anything that interests me. I play snooker (badly), archery (acceptably) and am a recovering Windows Phone user.