UniqueIdentifier as a primary key, that will solve all of our problems!
No, no it won’t. In evolving a single-instance website to multi-instance one, one of the many problems I have faced is how to deal with database access when your website instances are on the opposite side of the world.
My solution to this was to use SQL Azure Data Sync, makes sense as my databases are already in SQL Azure anyway.
Facilitating this involved changing all of the integer primar keys of every table to a different type with a lower possibility of collisions when syncing between databases.
I thought a Guid in the .Net side and a UNIQUEIDENTIFIER in the database would be the perfect fit for this. I was very, very wrong.
While using uniqueidentifiers as PKs has virtually eliminated any possibility of a sync collision, there is a very undesirable side effect of very high index fragmentation, bringing my site crashing to it’s knees as soon as the indexes reach a critical level of fragmentation.
As is customary, I decided to run some tests. Below are the results of inserting 10k records in to an empty table:

Ouch! 96% fragmentation vs 18% on 10k records. Now in reality I rarely insert 10k records at the same time, but certain operations involve hundreds and this level of fragmentation will occur over the course of time.
Regardless of what data type your PKs are, fragmentation will happen. But the massive downside of using uniqueidentifier is that this not only happens a lot faster, but also a simple defrag or rebuild indexes is not going to save you as the data is inherently, due to it’s random nature, impossible to efficiently index.
My first idea was to use an identity column (in my case called clusterkey) for the clustered index and keep the PK as a Guid with the PK constraint being non-clustered. This would sort out the fragmentation problem. But unfortunately, SQL Azure Data Sync didn’t like my clusterkey, I suspect because it is a non-PK identity column. Regardless of the reason, it’s not viable, so I looked further.
A contact at Microsoft suggested using the SequentialId() function in SQL Azure (available as of the latest V12 release), but all of my Guids are generated in code, so this was too big a change for me. My colleague Dave came to the rescue by tracking down this article, which describes how to generate reasonably sequential guids in C# that should keep the clustered index happy.
I’ll not repeat the contents of the article, which is a really informative read, but it seems to work. This is how my tests look now:
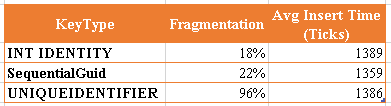
I’ll take that, much better fragmentation and approximately the same cost for inserts.
Note: The insert time includes the time taken to generate the Guid/SequentialGuid in code. Also, don’t take the fact that SequentialGuid is smaller here as an indication that it is consistently faster. During testing, the number was generally the same as Guids and ints, but was consistently faster as soon as I came to actually measuring it for this blog post!
As these kinds of distributed environments become more common, I suspect more and more people will hit similar issues so hopefully this will help someone avoid making the same mistakes I have.
About Alan Parr

I am a .Net developer based in the Midlands in the UK, working on Azure, .Net Framework, .Net Core, and just generally playing around with anything that interests me. I play snooker (badly), archery (acceptably) and am a recovering Windows Phone user.